J’ai fait le tour de tout ce qui concernait le DR dans la part I. Ici, je vais maintenant détailler les autres “petites nouveautés”.
Plus de détail sera apporté à la vue “Data Resiliency Status”. Je trouve que c’est pratique de retrouver l’information ici, rapidement, plutôt que d’aller chercher en ligne de commande. En image voici concrètement ce que cela donne pour un nœud en panne sur un cluster de 3 :

À savoir, le statut sera toujours noté “Computing” pendant un upgrade. J’avais déjà proposé une amélioration à ce sujet, pour mettre en sourdine les évènements liés à l’opération ce qui nous laisserait les logs plus lisibles, mais c’est en attente.
Ensuite, il y a un nouveau mécanisme d’optimisation concernant les snapshots, appelé Merge vBlock Metadata. Il permettra de limiter la perte d’IOPS avec les snapshots cumulatifs lorsque les metadatas ne proviennent pas du cache, ce qui arrive avec un changement de working set ou le reboot de stargate.
Dans le détail, lorsque nous avons une chaîne de snapshot, la donnée lue doit parfois traverser 6 entrées de vblock dans Cassandra contre 2 seulement avec les Merge vBlock. Concrètement, les gains sont de 30% sur de la lecture aléatoire au dixième snapshots et plus encore sur la relance d’un stargate.
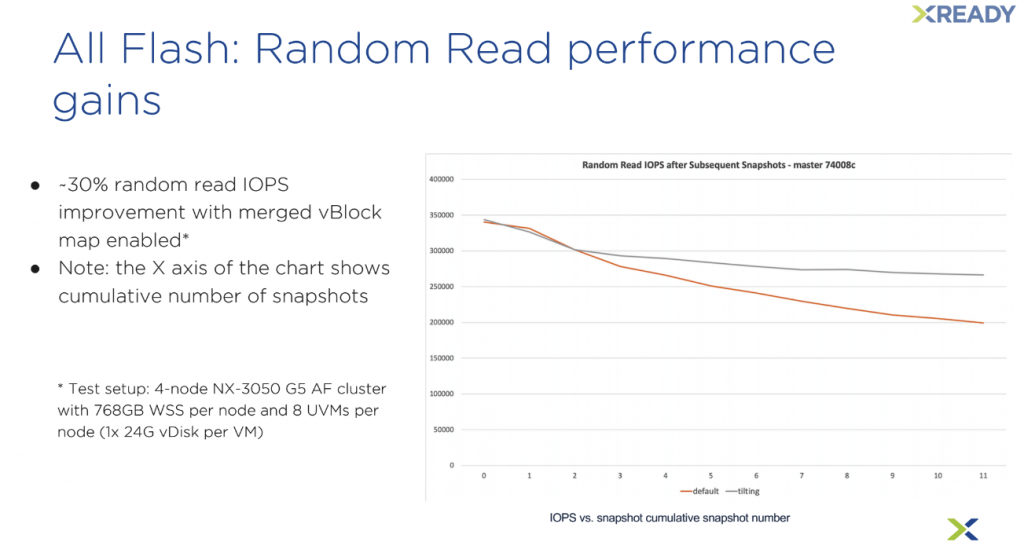
Par contre, cette fonctionnalité est volontairement limitée aux clusters qui disposent de nœud d’une capacité de stockage entre 60 et 70TB. Cette limitation baissera avec le temps. Autre limitation, mais qui ne changera pas, Merged vblock est automatiquement désactivé s’il y a la de-duplication activée sur le conteneur. Bonne nouvelle cette technologie n’est pas soumise à un licensing particulier et tous les hyperviseurs pourront en bénéficier.
La fonctionnalité Rack Awareness est également disponible sur Hyper-V, donc tous les hyperviseurs sont maintenant supportés.
En 5.17, Nutanix Volumes supporte officiellement Windows Server 2019, idéal pour les serveurs bare metal et le Windows Failover Cluster.
Enfin la simplification du clustering avec Volumes qui supporte les réservations persistantes SCSI-3, qui évitera d’aller dans la VM pour réaliser la connexion iSCSI.
L’Erasure Coding est maintenant pleinement opérationnel avec Autonomous Extent Store (AES). Pour rappel AES introduit en 5.11 permet l’amélioration des performances en conservant une partie des metadatas sur le nœud qui exécute le worload. Nutanix Bible parle de METAdata locality, je trouve ça très explicite.
Pour terminer, le licensing pour Object est maintenant géré depuis Prism Central. Mercury sera la nouvelle passerelle API développé en C++ pour diverses optimisations et Prism Central pourra supporter jusqu’à 300 clusters (avec un noeud chacun) et 25 000 VMs. Uniquement pour les nouveaux déploiements de Prism Central, il y aura la possibilité d’améliorer les performances en répartissant la charge sur plusieurs vDisks.
N’hésitez pas à donner votre avis en commentaire, mais je trouve cette mise à jour impressionnante. Elle apporte une réponse à ce que pas mal de clients demandent depuis quelque temps. Même si tout n’est pas encore implémenté, les briques sont là et les prochaines versions viendront améliorer tout ça !