Ça y est, la première STS est disponible, voici la liste des nouvelles fonctionnalités à lire attentivement pour les plus pressés qui voudraient déjà l’implémenter :
IP Set-based Firewall : La fonction de pare-feu basée sur l’ensemble d’adresses IP permet de mettre en place des règles de pare-feu strictes pour la communication intra-cluster. Elle ne permet de recevoir des demandes RPC et API des adresses IP individuelles des VMs de contrôleur et des hyperviseurs considérés comme des sources de confiance. Il est possible d’activer cette fonction en suivant les instructions du guide de sécurité AOS 6.6.
Disk Health Monitor : Cette version améliore les vérifications de santé de disque existantes et le nettoyage de données en continu pour réagir plus rapidement à un signal de santé de disque. La fonction de surveillance de la santé des disques (DHM) effectue des vérifications de santé SMART périodiques sur les disques d’un cluster et vous alerte lorsqu’un disque est sur le point de tomber en panne. Cette fonction est activée dès la création d’un cluster et désactivée lors de la destruction d’un cluster. Si DHM détecte qu’un disque n’est pas en bonne santé, une alerte PhysicalDiskPredictiveFailure est générée, et celle-ci peut être consultée dans le tableau de bord des alertes de la console web Prism. Il y a une FAQ qui décrit le nouveau Disk Health Monitor et une KB qui décrit l’alerte et les moyens pour la résoudre : Alert – PhysicalDiskPredictiveFailure .
Cross-vDisk Strips Inline Erasure Coding : Il est maintenant possible de configurer l’Erasure Coding à travers des Strips vDisk dans un conteneur de stockage. Dans ce type d’Erasure Coding en ligne, les Strips sont créées à l’aide des blocs de données à travers plusieurs vDisks. Nutanix recommande de configurer le type d’Erasure Coding en ligne comme des Strips de vDisk croisées pour les VMs qui nécessitent la data locality.
IP-less Communication Between NGT and CVM : Cette version supporte la communication sans IP entre NGT et CVM sur les clusters AHV. La communication sans IP améliore la sécurité de la liaison de communication, car elle ne nécessite pas que le CVM soit accessible par la VM via le réseau. Le service NGT communique avec le CVM via des connexions sans IP en utilisant le premier port série sur l’UVM. Si le CVM ne répond pas, NGT revient à la communication basée sur IP. Ce point devrait intéresser pas mal de client.
Native Encryption of Replication Traffic : Cette version supporte le chiffrement à la volée pour le trafic de réplication des Protection Domain. Le chiffrement est désactivé par défaut pour réduire la surcharge CPU pour les flux de données sur des connexions déjà chiffrés tels que les connexions VPN. La fonctionnalité s’active en ligne de commande.
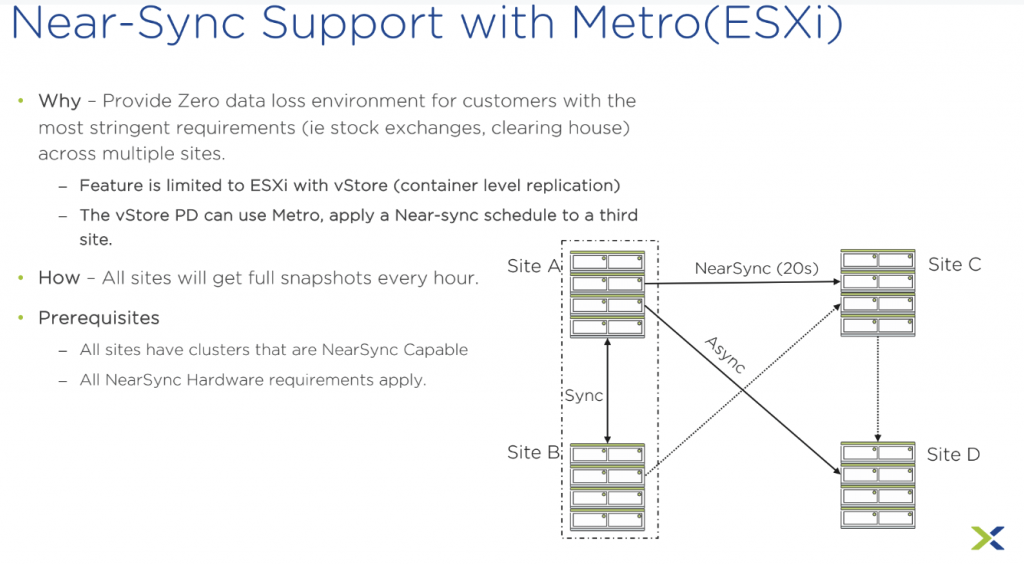
Autonomous NearSync : Cette version supporte la planification de réplication NearSync autonome qui génère un flux continu d’instantanés. Le domaine de protection NearSync génère un flux d’instantanés locaux pour des créneaux de 15 minutes. Avec Autonomous NearSync, un widget vous permet de sélectionner un temps de synchronisation à la seconde près.
Service-level Network Traffic Segmentation in Nutanix Disaster Recovery : Il est maintenant possible d’isoler le trafic réseau du service Nutanix Disaster Recovery en cours d’exécution entre deux clusters Nutanix. La segmentation de trafic réseau améliore la sécurité, la résilience et les performances du cluster en isolant un sous-ensemble de trafic sur son propre réseau et nécessite une segmentation réseau physique sur les clusters.
Disaster Recovery of Volume Groups and Consistency Groups : Il est désormais possible de protéger les groupes de volumes et les groupes de cohérence avec les VMs dans Disaster Recovery. Seuls les réplications asynchrones entre les clusters Nutanix supportent la protection des groupes de volumes et de cohérence. Le mécanisme de basculement défini dans les plans de récupération orchestre la récupération de sinistre des entités protégées (groupes de volumes, groupes de cohérence et les VMs invitées associées).
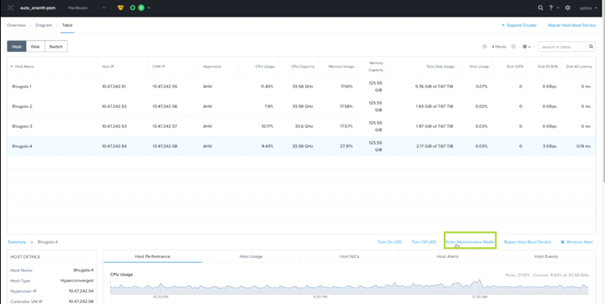
Node Maintenance Mode for ESXi Nodes : L’interface utilisateur Prism prend à présent en charge la mise en mode maintenance “en douceur” des hôtes ESXi pour des raisons telles que les modifications de la configuration réseau d’un nœud, les mises à niveau ou remplacements de firmware manuels, l’entretien CVM ou toute autre opération d’entretien. Je ne sais pas ce qu’ils entendent par “en douceur”, il va falloir tester.
RDMA Pass-through Mechanism : Cette version supporte le RDMA Pass-through après la création d’un cluster via l’interface utilisateur Prism. Cela s’ajoute au RDMA Pass-through existant lors de l’installation de la fondation. Dans ce cas, le comportement suivant est applicable : Si le RDMA Pass-through est effectué lors de l’installation de la fondation : la CVM réserve l’intégralité de la NIC pour le passage de port RDMA. L’hôte ne peut pas utiliser le port NIC vide pour d’autres opérations, ni changer le port sélectionné. Si le RDMA Pass-through n’est pas effectué lors de l’installation de la fondation : le système vous offre une option pour réserver le port éligible pour RDMA. Cette fonctionnalité est disponible uniquement avec l’hyperviseur AHV.
Zero Touch RDMA (ZTR) Support : Zero Touch RDMA (ZTR) est un mécanisme de déploiement pour la configuration RDMA dans lequel le firmware de la carte réseau Mellanox gère toutes les configurations (contrôle de flux) sans intervention de l’utilisateur ou dépendance des profils de commutateur personnalisés ou de la compatibilité de commutateur. ZTR réduit la durée de déploiement de RDMA et n’exige pas le support des paramètres de contrôle de flux basé sur la priorité (PFC) et de notification de congestion bout-à-bout (ECN). La fonctionnalité ZTR est prise en charge avec les hyperviseurs ESXi et AHV.
Nutanix recommande d’utiliser ZTR seulement si des adaptateurs Ethernet NVIDIA Mellanox Connect X-5 (cartes réseau Cx5) sont disponibles dans votre configuration. Pour plus d’informations sur la compatibilité des cartes réseau pour la fonctionnalité ZTR, consultez la matrice de compatibilité des cartes réseau pour les fonctionnalités RDMA dans le guide de sécurité.
Securing AHV VMs with Virtual Trusted Platform Module (vTPM) : AHV vTPM est une émulation logicielle de la puce TPM 2.0 physique qui fonctionne comme un périphérique virtuel. Vous pouvez utiliser la fonctionnalité AHV vTPM pour sécuriser les machines virtuelles exécutant sur AHV en utilisant Prism Central.
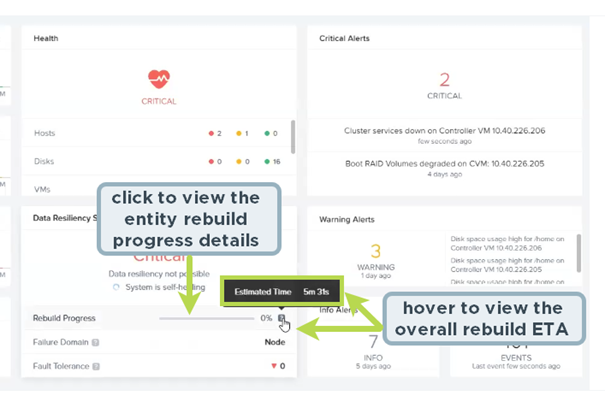
Support for Cluster Resiliency Preference : Nutanix AOS fournit une capacité de résilience de cluster pour protéger vos clusters contre toutes les défaillances. L’opération de reconstruction nécessite un stockage supplémentaire sur le cluster et peut ne pas être nécessaire pour un cluster qui subit une maintenance planifiée. Pour de telles opérations de maintenance planifiées (comme les mises à niveau de logiciel ou de firmware), vous pouvez retarder le déclencheur de reconstruction en définissant la préférence de résilience en utilisant nCLI.
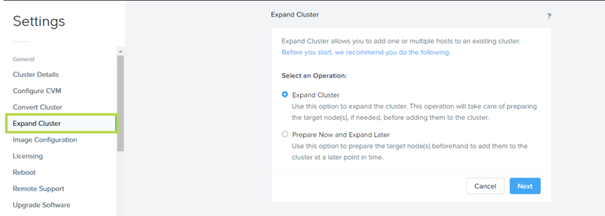
Unregister a Cluster from a Disconnected Prism Central : Il est maintenant possible de supprimer l’enregistrement d’un cluster de Prism Central même lorsque les deux entités ne sont plus connectées. Vous devez effectuer des étapes spécifiques sur Prism Central ainsi que sur Prism Element (cluster). On pouvait le faire en ligne de commande, on dirait que l’opération a été simplifié ici.
AOS Kernel Migrated to Upstream, Kernel.org Provided, Long Term Support (LTS) Kernel Branch :
La mise à niveau du noyau 5.10 LTS sur la machine de contrôle (CVM) fait partie de l’amélioration de la posture de sécurité du produit : Meilleur contrôle de la stratégie de mise à jour des correctifs Nutanix CVE. Rester à jour avec les correctifs de bogues du noyau en amont, les mises à jour des pilotes, etc. Meilleures performances pour la CVM.
Intelligent Distributed Disk Scrubbing : Avec cette fonctionnalité, AOS forme une vue globale des activités de nettoyage sur le cluster et sélectionne les données les plus vulnérables à valider en fonction des contraintes de calcul et d’E/S.
Enabled Server Side Session Management in Mercury : Cette version permet la gestion de session côté serveur dans Mercury pour fournir les améliorations suivantes par rapport à la gestion côté client : La déconnexion invalide les cookies. Vous pouvez invalider les cookies à tout moment. Les sessions utilisateur existantes sont déconnectées après la mise à niveau vers AOS 6.6 ou les versions ultérieures. Vous devez vous reconnecter après la mise à niveau. Le nombre maximum de sessions actives simultanées autorisées est de 1 000.
Improved Garbage Collection : Cette version introduit une nouvelle fonctionnalité qui supprime automatiquement les extents partielles des clusters qui ont un I/O fragmenté et ont des instantanés AOS pris de manière régulière. Par défaut, cette fonctionnalité empêche les d’extents partielles d’occuper plus de 10% de l’espace utilisé total dans vos clusters. Ce nombre peut être configuré en contactant le support Nutanix.