AOS 6.5.1 est disponible depuis quelques jours à peine, cette version introduit le support d’Hyper-V 2022 sur les plateformes NX.
La version d’AHV associée (AHV-20201105.30411) n’apporte qu’une correction de bug relative au Uncorrectable Error Correction Code (UECC).
Rien de très intéressant me direz-vous mais à partir de cette base vous pouvez upgrader en 20220304.242 soit la version AHV 8.0 dont voici quelques points :
support du vTPM pour les VMs AHV (enfin !)
support de Windows 11 dont 22H2: il faudra respecter les prérequis suivant mais l’ajout du vTPM était vraiment le point bloquant pour Windows 11 :
Secure boot activé
VirtIO 1.2.1
UEFI
vTPM
Support de Windows Sybsystem for Linux (WSL2)
En plus ce ça sous le capot, les performances de stockage ont été amélioré, les mesures par X-RAY indiquent une amélioration jusqu’à 15% pour les écritures aléatoires 8k et jusqu’à 3% pour la lecture-écriture en séquentielle pour des blocs de 1MB. Amélioration des performances spécialement en cas de forte densité de machines +22% sous VSIMax. Il semble y avoir pas mal d’autre points relatif à la récupération des performances perdu suite à la correction de problèmes de sécurité.
Les plus téméraires d’entre vous pourrons bénéficier dès maintenant de toutes ses améliorations, ou vous pouvez simplement attendre AOS 6.5.2 qui inclura AHV 8.0.
Partager la publication "AOS 6.5.1 – AHV 8 et Windows 11"
J’ai fait le tour de tout ce qui concernait le DR dans la part I. Ici, je vais maintenant détailler les autres “petites nouveautés”.
Plus de détail sera apporté à la vue “Data Resiliency Status”. Je trouve que c’est pratique de retrouver l’information ici, rapidement, plutôt que d’aller chercher en ligne de commande. En image voici concrètement ce que cela donne pour un nœud en panne sur un cluster de 3 :
À savoir, le statut sera toujours noté “Computing” pendant un upgrade. J’avais déjà proposé une amélioration à ce sujet, pour mettre en sourdine les évènements liés à l’opération ce qui nous laisserait les logs plus lisibles, mais c’est en attente.
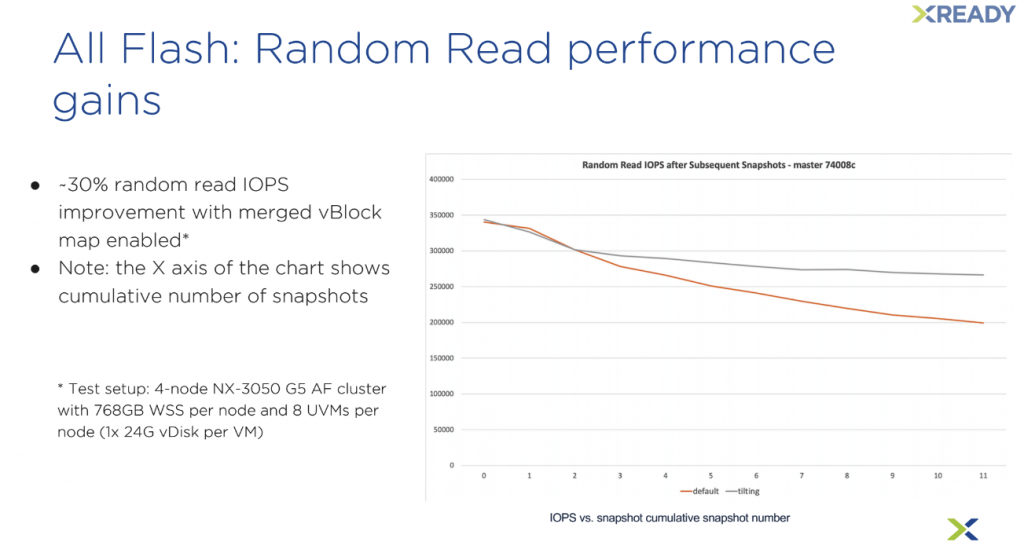
Ensuite, il y a un nouveau mécanisme d’optimisation concernant les snapshots, appelé Merge vBlock Metadata. Il permettra de limiter la perte d’IOPS avec les snapshots cumulatifs lorsque les metadatas ne proviennent pas du cache, ce qui arrive avec un changement de working set ou le reboot de stargate.
Dans le détail, lorsque nous avons une chaîne de snapshot, la donnée lue doit parfois traverser 6 entrées de vblock dans Cassandra contre 2 seulement avec les Merge vBlock. Concrètement, les gains sont de 30% sur de la lecture aléatoire au dixième snapshots et plus encore sur la relance d’un stargate.
Par contre, cette fonctionnalité est volontairement limitée aux clusters qui disposent de nœud d’une capacité de stockage entre 60 et 70TB. Cette limitation baissera avec le temps. Autre limitation, mais qui ne changera pas, Merged vblock est automatiquement désactivé s’il y a la de-duplication activée sur le conteneur. Bonne nouvelle cette technologie n’est pas soumise à un licensing particulier et tous les hyperviseurs pourront en bénéficier.
La fonctionnalité Rack Awareness est également disponible sur Hyper-V, donc tous les hyperviseurs sont maintenant supportés.
En 5.17, Nutanix Volumes supporte officiellement Windows Server 2019, idéal pour les serveurs bare metal et le Windows Failover Cluster.
Enfin la simplification du clustering avec Volumes qui supporte les réservations persistantes SCSI-3, qui évitera d’aller dans la VM pour réaliser la connexion iSCSI.
L’Erasure Coding est maintenant pleinement opérationnel avec Autonomous Extent Store (AES). Pour rappel AES introduit en 5.11 permet l’amélioration des performances en conservant une partie des metadatas sur le nœud qui exécute le worload. Nutanix Bible parle de METAdata locality, je trouve ça très explicite.
Pour terminer, le licensing pour Object est maintenant géré depuis Prism Central. Mercury sera la nouvelle passerelle API développé en C++ pour diverses optimisations et Prism Central pourra supporter jusqu’à 300 clusters (avec un noeud chacun) et 25 000 VMs. Uniquement pour les nouveaux déploiements de Prism Central, il y aura la possibilité d’améliorer les performances en répartissant la charge sur plusieurs vDisks.
N’hésitez pas à donner votre avis en commentaire, mais je trouve cette mise à jour impressionnante. Elle apporte une réponse à ce que pas mal de clients demandent depuis quelque temps. Même si tout n’est pas encore implémenté, les briques sont là et les prochaines versions viendront améliorer tout ça !
Partager la publication "Quoi de neuf ? AOS 5.17 : Partie II"
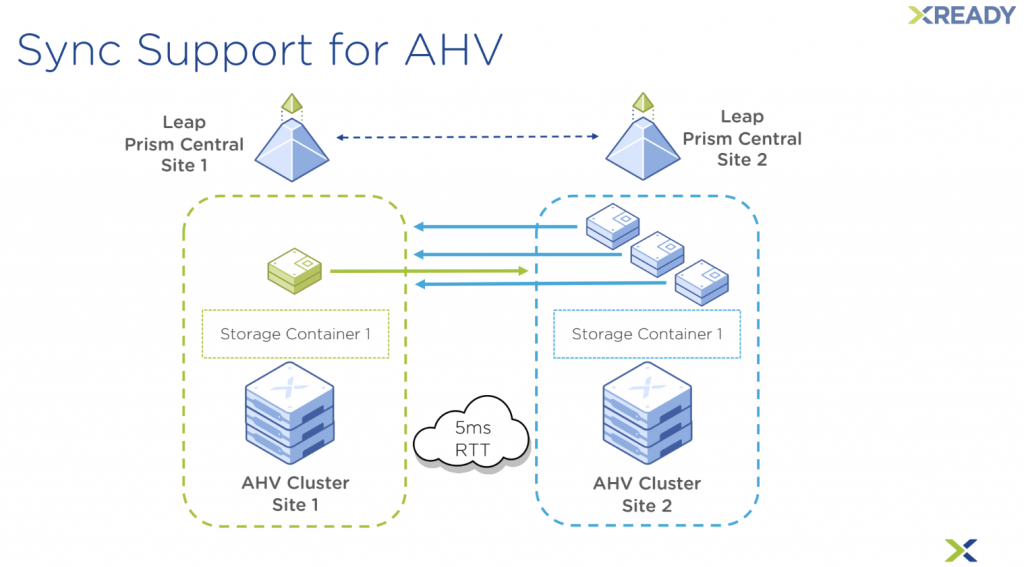
Je ne vais pas faire durer plus longtemps le suspense, la réplication synchrone est arrivée sur AHV ! Cette release est le grand pas en avant que beaucoup de clients attendaient pour tout ce qui concerne la reprise sur sinistre (Disaster Recover – DR).
À nous le RPO 0, la simplicité de configuration d’une seule stratégie qui protégerait toutes nos VMs Mission Critical ! Contrairement au métro cluster sur ESXi qui fonctionne par datastore, ici la granularité est à la VM. On peut la mettre en pause, la stopper et l’appliquer au travers de catégories.
Concernant les contraintes et prérequis un petit schéma vaut mieux que mille mots :
En premier lieu, il faut un Prism Central (PC) sur chaque site. Pour cette première version, seule la bascule non planifiée (unplanned failover) est supportée. La bascule planifiée viendra par la suite pour démontrer aux divers auditeurs que vous avez testé votre scénario de bascule. Si vous lancez quand même la bascule aujourd’hui pour tester, cela généra un split brain. Il est conseillé d’éteindre les VMs avant 😉
Dans la même veine, pas d’option pour un témoin (witness), mais c’est prévu. Le failback fonctionne de la même façon (unplanned failover, éteindre les VMs, récupérer depuis le dernier point de récupération ou plus loin dans le temps comme sur Metro).
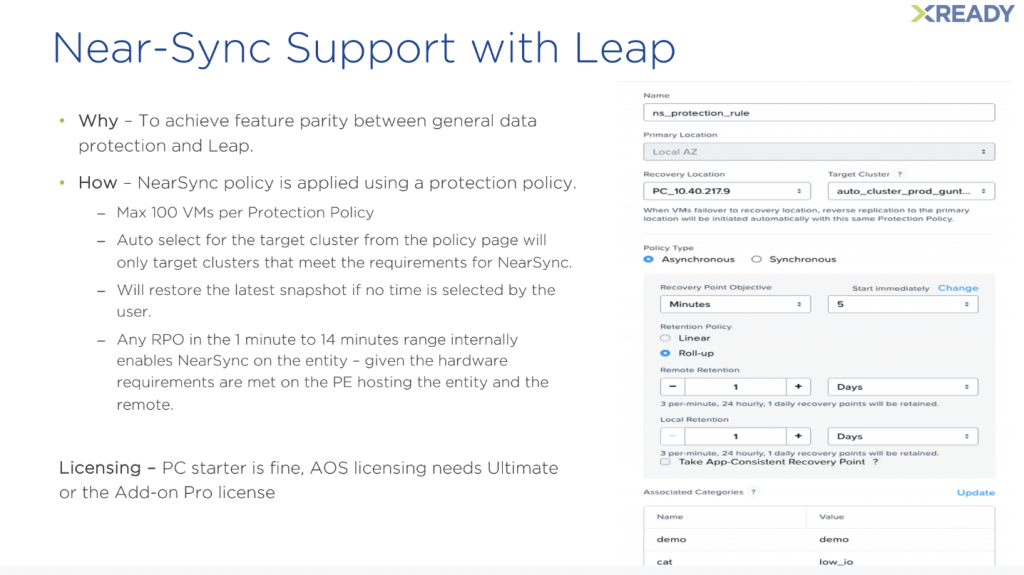
Pour les environnements qui ne nécessitent pas un RPO 0, il y a le Near-Sync d’une à quatorze minutes. Near-Sync était déjà disponible au niveau des Protections Domains historiques. Il est ici question de l’implémentation dans Leap, le moteur de bascule utilisé pour XI Leap. Pas de changement concernant les anciens prérequis du Near-sync. Enfin, la protection ne concerne que 100 VMs pour le moment, et cela devrait rapidement doubler.
AOS 5.17 apporte aussi le support d’un seul Prism Central pour Leap, s’il est utilisé pour les réplications asynchrones donc tout ce qui est au-delà de l’heure. Pas de Cross-Hypervisor DR non plus, la source et la destination doivent avoir le même hyperviseur, enfin le PC et le Prism Element (PE) doivent être en 5.17 tous les deux et disposer du mappage réseau dans le plan de récupération.
Single PC support for Leap
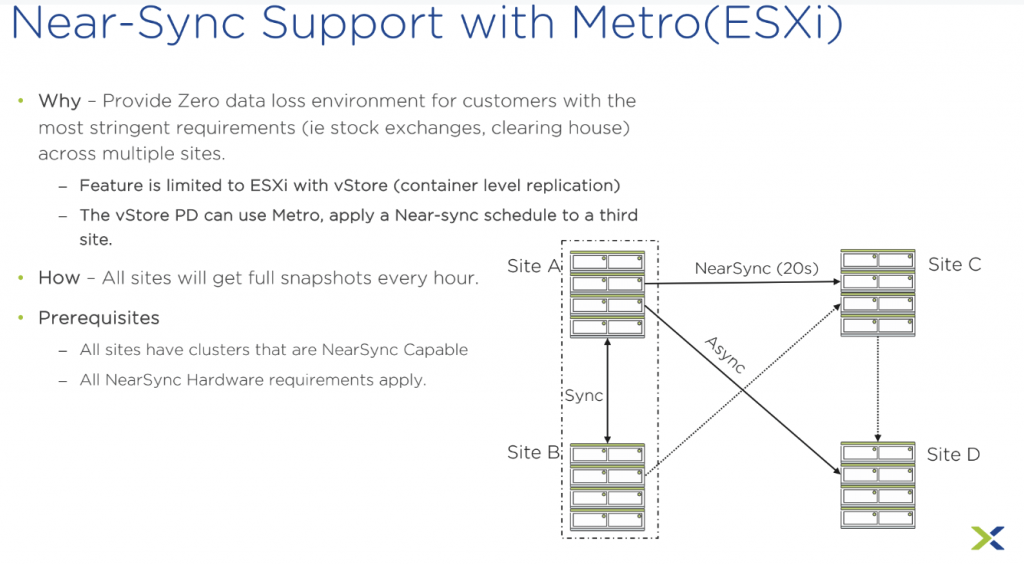
Enfin pour Metro ESXiuniquement, le support du near-sync, alors là vous vous dites que j’ai bugué, moi aussi je suis resté bloqué un moment pour comprendre. En plus du Metro entre votre Site A et B, vous cumulez le NearSync avec un site C, et si vous avez un site D (Flush Flash uniquement) vous pouvez ajouter une réplication Async de 3 minutes au niveau du conteneur. Le tout pilotable avec Site Recovery Manager (SRM) de VMware, en plus de Prism Element ! Ce scénario ne devrait intéresser qu’un petit nombre de clients haut de gamme avec des besoins vraiment spécifiques.
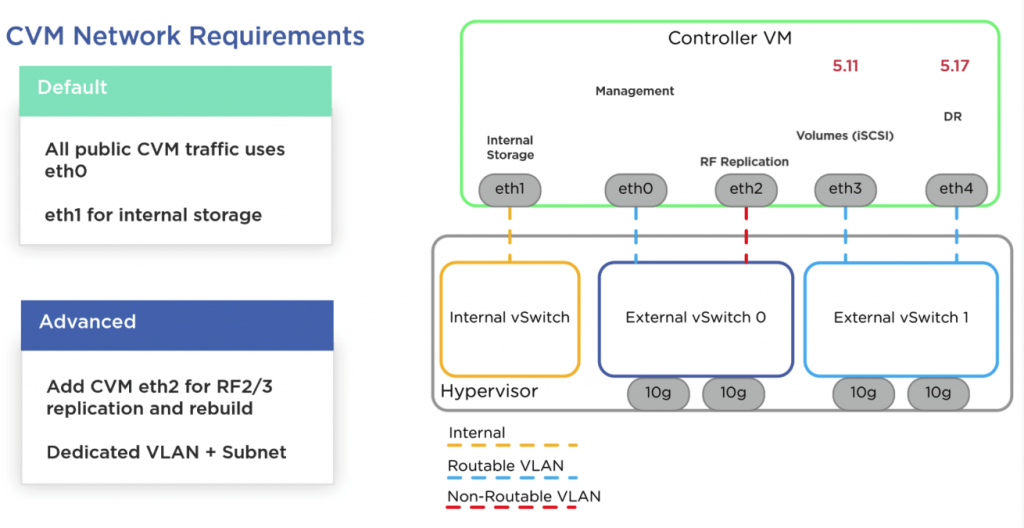
Demandé par de nombreux clients qui ont à cœur la séparation de leur flux réseaux pour des questions de sécurité principalement, et qui avaient sûrement déjà isolé leur flux Volumes (iSCSI) depuis la 5.11, voici la segmentation réseau pour la Réplication. Nous aurons la possibilité de créer un nouveau réseau pour la réplication externe. Supporté par ESXi et AHV, ce n’est pas compatible Leap, mais uniquement sur les Protections Domains. Attention, cela concerne plutôt les nouvelles installations. Sinon vous devrez supprimer le site distant et le refaire après avoir créé la nouvelle VIP pour ce trafic.
CVM Network Isolation
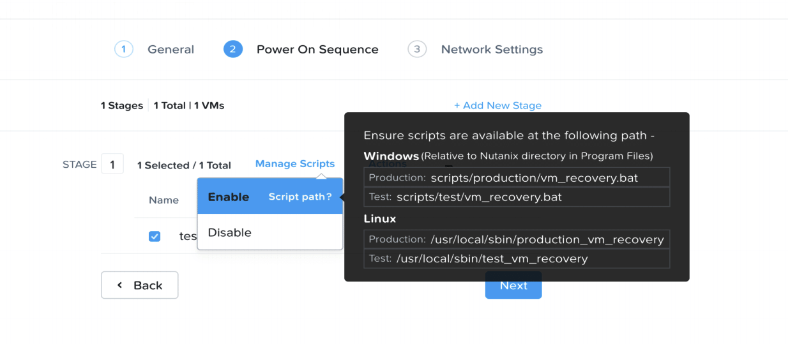
À la façon d’un VMware SRM, nous pouvons maintenant faire du mappage d’adresse IP statique dans Leap, ainsi que lancer un script pendant la séquence de démarrage de la VM :