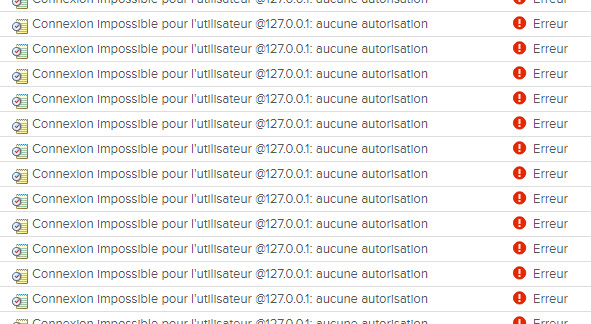
Si vous rencontrez ce message d’erreur sur vos ESXi, vous utilisez sûrement vSphere Replication. Habituellement, les journaux d’événements des ESXi sont remplis d’événements “User root@127.0.0.1 logged in as hbr-agent” ou en français “L’utilisateur root@127.0.0.1 est connecté en tant que hbr-agent”.
J’ai récemment été contraint d’activer le lockdown mode. C’est une fonctionnalité de verrouillage qui permet d’éviter les interactions directes avec l’ESXi et ne permet son administration qu’au travers du vCenter.
Cet article de VMware détaille bien mieux que moi le fonctionnement des deux modes de verrouillage.
Mais vous l’aurez compris, vSphere Replication ne semble pas vouloir utiliser le vCenter et se connecter directement en root sur les ESXi.
Ajouter le root en exception, comme on me l’a proposé, équivaut pour moi à l’annulation du lockdown mode.
Après des semaines de bataille avec le Global Support Services, où ils m’étaient en cause des vibs HPe présentent sur les builds, le ticket est maintenant escaladé auprès des développeurs.
Je suis pour ma part assez surpris d’en arriver là. L’utilisation conjointe de vSphere Replication et Lockdown mode doit vraiment être exceptionnelle pour que le “bug” ne remonte que maintenant au dev. D’autant plus que j’utilise vSphere Replication depuis des années et l’utilisation du compte root me semble présent dans son ADN depuis un moment.
N’étant pas particulièrement fan du lockdown mode, j’ai prévenu le support qu’une simple déclaration officielle incompatibilité avec vSphere Replication m’irait très bien. Je mettrais à jour cet article lorsque j’aurais du nouveau. En attendant, j’ai temporairement une exception pour la désactivation de cette fonctionnalité.
Update 1er Septembre du GSS : “There is no impact to replication jobs with lockdown mode enabled. It will cause extra logging in vCenter. No workaround at present for the extra logging. Recommendation is to disable Lockdown mode”.
Partager la publication "Cannot login user @127.0.0.1: no permission – Connexion impossible pour l’utilisateur @127.0.0.1: aucune autorisation"
Nous n’arrivions pas à faire de remédiation d’un hôte ESXi, il fallait forcément le passer en maintenance “manuellement” avant, ce qui est fort peu pratique quand il y a plusieurs dizaines d’ESXi à mettre à jour.
La remédiation échouait avec les messages “Another Task is already in progress / Une autre tâche est déjà en cours.” et “The task failed because another task is currently in prgress. Either your task, the task that is in progress, or both tasks require exclusive execution. / La tâche a échoué car une autre tâche est actuellement en cours d’exécution. Votre tâche, la tâche qui est en cours d’exécution ou les deux tâches nécessitent une exécution exclusive”.
Dans les logs, on constate effectivement deux taches lancées en même temps par 2 composants :
La tache en erreur de com.vmware.vcIntegrity correspond à VMware Update Manager, com.vmware.vcHms correspond à vSphere Replication, mais pourquoi lancent-ils une tache en même temps ?
En premier lieu, nous vérifions la présence des vibs sur les ESXi
localcli software vib list | egrep -i "vr2c|hbr"
localcli software vib get | egrep -i "vr2c|hbr"
Les vibs sont bien installées, le workaround consiste à désactiver l’option d’installation automatique des vibs de vSphere Replication afin de ne plus entrer en conflit avec Update Manager, ce qui aura comme conséquence de devoir installer ces vibs “manuellement” sur les nouveaux ESXi.
Après ces opérations, je lance une remédiation sur un des ESXi et l’opération de patching se passe correctement.
Je ne suis pas pleinement satisfait, car même si le patching se déroule normalement, des opérations supplémentaires sont à prévoir à l’installation de nouveau nœud, mais je vous indique une partie de la réponse du support à ce sujet : “There is no projected fix for this issue presently. Engineering are only providing us with the VR vib ‘auto-install’ disable option. New hosts added to the cluster require a manual vib install or you can include the vib in a VUM baseline.”
J’essaye donc d’appliquer cette dernière recommandation et de créer une nouvelle baseline avec les vibs en suivant la KB75321.
Après récupération des vibs comme dans la procédure, j’essaye d’importer celle-ci dans Update Manager, mais j’ai un message d’erreur :
Il s’avère que le fichier fourni ne permet pas l’importation dans VMware Update Manager, il sert uniquement à l’installation sur l’ESXi. Le support est au courant et m’a confirmé qu’il n’y aurait pas d’autre workaround pour ce problème et m’a même conseillé de soumettre une feature request… Ce n’est pas une feature que d’avoir les deux produits qui fonctionnent “normalement” dans son infrastructure…
Partager la publication "Échec de Remédiation VMware Update Manager à cause de vSphere Replication"
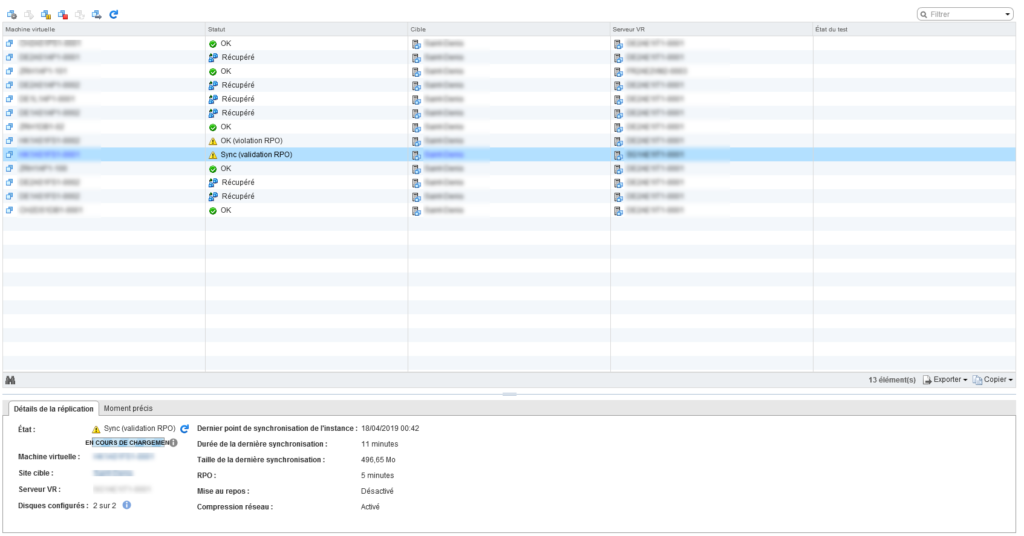
J’avais apparemment un problème de synchronisation avec vSphere Replicaton. Le redémarrage des appliances réglait temporairement le problème, mais invariablement le dernier point de synchronisation semblait se bloquer sur toutes les machines au même moment.