La nouvelle version Long Term Support d’AOS est disponible depuis cet été, je vais essayer ici de détailler toutes les optimisations et ajouts de fonctionnalités pour cette version majeure qui sera le socle pour les prochaines mois.
Improved Single vDisk Performance : Anciennement le contrôleur de stockage était monothreadé, avec AOS 6.5, même les VMs avec un seul contrôleur pourront tirer parti du multithreading ce qui améliore les performances pour les machines avec un seul gros vdisk.
Enhanced NearSync Replication Schedules for VStore Protection : La réplication NearSync peut maintenant descendre jusqu’à 20 secondes entre deux sites.
Storage Containers: Provision a Storage Container with Replication Factor 1 : Attendu depuis longtemps la possibilité de provisionner un conteneur de stockage avec une seule copie des données, c’est très économique en espace, mais évidemment c’est à réserver aux workloads qui ont leur propre mécanisme de redondance et protection de la donnée car en cas de défaillance la donnée ne sera plus disponible.
IPv6 Enablement in a Cluster : Possibilité d’activer l’IPv6 sur un cluster AHV avec la commande manage_ipv6, attention le cluster ne doit pas etre connecté à un Prism Central.
DR Dashboard: Monitoring and Reporting : depuis Leap, un dashboard permet de surveiller l’état de préparation des opérations de reprise, plusieurs vues sont disponibles et la génération de rapports détaillés sur la santé des réplications et des opérations est facilité.
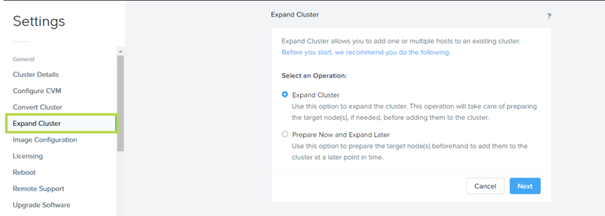
Expand Cluster Redesign : Il est maintenant possible de préparer un nœud pour étendre un cluster puis de l’ajouter plus tard, ou bien procéder à l’extension immédiate comme précédemment. Cluster Expand prend maintenant en charge les clusters en LACP (AHV et Hyper-V) et l’ajout de Storage-Only node directement depuis l’interface.
Enhanced Asynchronous Replication Schedules : Je n’ai pas trouvé beaucoup d’informations sur ce point, mais il y a un nouveau mécanisme rétrocompatible qui améliore la planification des réplications asynchrones dans Leap.
Reserve Rebuild Capacity : Il est ici possible de cocher une case qui vous empêchera de remplir le stockage du cluster au-delà du seuil ou la reconstruction de la redondance n’est plus possible.
Mixed Storage Capacity Support for Hardware Swap : Permet de remplacer un disque dur par un autre de capacité supérieure, très utile lorsqu’un le fabricant n’a plus la référence d’origine en stock, et ça tombe très bien, j’ai justement eu le cas chez un client. La capacité globale du cluster ne sera pas augmentée à moins de remplacer tous les disques, le remplaçant est simplement pris en charge avec la capacité de celui qu’il remplace.
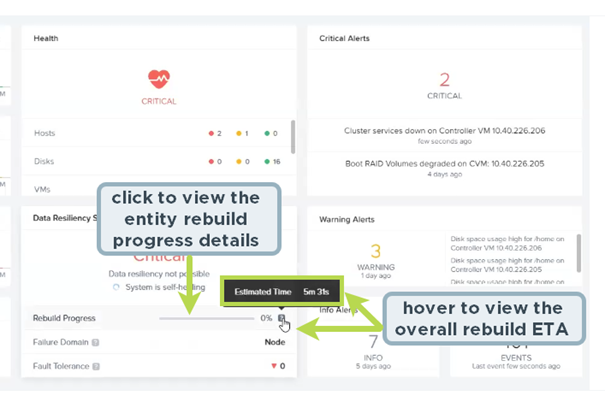
Rebuild Progress Indicator and ETA : Cette amélioration indique la progression de la reconstruction des données. Je trouve cette amélioration très pratique, d’un coup d’oeil sur le dashboard principal on peut obtenir une estimation du temps restant pour l’opération.
VSS Snapshot Backup type change : Modification du type de sauvegarde pour les snapshots VSS par défaut en VSS_BT_COPY à la place de VSS_BT_FULL.
Flow Networking with Virtual Private Cloud and Virtual Private Network Support : Il faudra probablement un article détaillé tant les améliorations sont nombreuses !
Recycle Bin: Clear Space Used by Recycle Bin : Vous pouvez supprimer le contenu de la corbeille depuis Prism. /!\ Il n’y a pas de corbeille pour les conteneurs en RF1.
Physically Isolate Backplane Traffic on Hyper-V : L’isolation physique du trafic backplane est maintenant disponible sur Hyper-V.
Ability to Upgrade Flow as an Independent Service : Flow peut être mis à jour via LCM, malgré cette indépendance, le service a quand même besoin d’être aligné sur les versions d’AOS et Prism Central pour des raisons de compatibilités.
Enhanced Security with Restricted Shell Access : Ajoute une fonctionnalité ou vous devez contacter le support Nutanix pour déverrouiller la configuration de sécurité et autoriser les modifications. Nouvelles restrictions pour le compte nutanix afin de forcer d’encourager les utilisateurs à utiliser le compte ‘admin’.
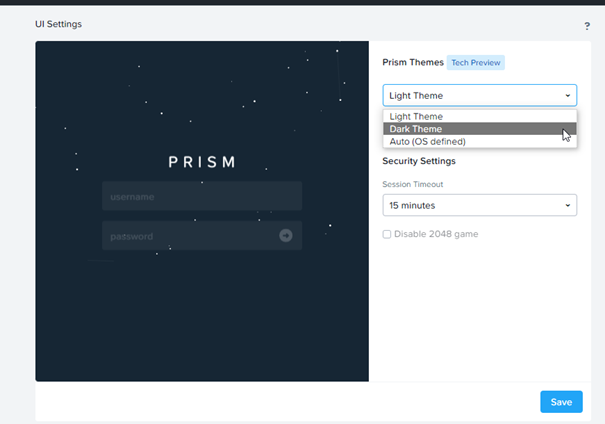
Dark Theme on Prism UI : Le thème sombre est disponible ainsi que la possibilité de s’appuyer sur le thème de votre OS pour choisir ce dernier.
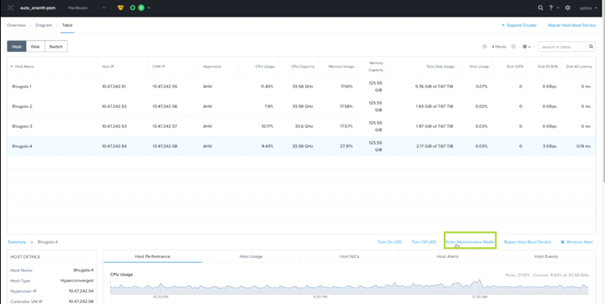
Whole Node Maintenance Mode : il est maintenant possible de mettre en maintenance directement depuis l’interface Prism – AHV 6.5 – Putting a Node into Maintenance Mode (AHV) (nutanix.com)
VM Centric Storage Policy : Possibilité de gérer des stratégies d’optimisation de stockage depuis Prism Central, ces stratégies s’appliquent aux VMs, à la façon d’une Storage Policy VMware.
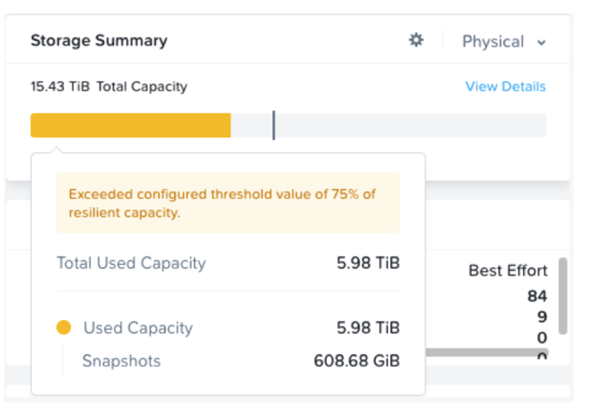
Space Reporting Enhancements in Storage Summary Widget : Depuis Prism Central le widget affiche plus de détail sur l’utilisation de l’espace de stockage.
NGT: Windows Performance Monitor (perfmon) Integration : ajout de deux métriques disponibles depuis perfmon hypervisor_cpu_usage_ppm qui indique le pourcentage de temps processeur de la machine et hypervisor_cpu_ready_time_ppm qui indique le pourcentage de ready time de la VM.
Support for In-place Entity Restore with Leap Recovery Points : Permet de restaurer une VM avec exactement les mêmes paramètres qu’elle avait sur l’AZ d’origine, les propriétés telles que l’UUID, le routage, la mac address, le hostname sont récupérés.
Support for Microsoft Windows Server 2022 : Pas grand-chose à ajouter….
Enhanced Cluster Expansion Capabilities : Possibilité d’ajouter plusieurs nœuds à la fois.
Network Segmentation Enhancements : beaucoup de petite amélioration sur la network segmentation qu’il faudra probablement décrire dans un article dédié, mais il est possible d’ajout un petit Pool d’ip plutôt que tout un subnet, il est possible d’activé la fonctionnalité dans un cluster ESX ou Hyper-V malgré un noeud storage-only nodes (car sous AHV), possibilité d’assigner les IP à chaque CVM. Et Enfin support de la fonctionnalité avec Hyper-V.
Optane Tier for NVMe : Reproduit l’architecture historique SSD + HDD avec des tiers de performances cette fois ci entre les disques Optane pour le tier 0 et les SSD NVMe pour le tier 1.
Removing Multiple Nodes from a Cluster : Permet de retirer plusieurs noeuds d’un cluster, le retrait est séquentiel mais les nœuds marqués pour suppression ne récupèrent pas de données.
Support for New Utility Actions for Playbook : Ajout de 3 nouvelles actions pour les playbooks :
- Lookup Cluster Details
- Lookup Host Details
- Lookup VM Details
Support for SAML Users, SAML Groups and Organizational Units (OUs) : Ajout de la prise en charge des utilisateurs SAML, des groupes SAML et des OUs pour l’attribution des roles dans le RBAC de Prism Central.
Support for New CHAP Algorithms for Volumes : Pour les clients linux sur CentOS 8 ajout des algorithmes SHA1 et SHA256, Nutanix recommande de les utiliser pour authentification CHAP à la place des authentifications par défaut en MD5.
Support for Storage only Nodes When Expanding Clusters : Possibilité d’ajouter un Storage Only Node directement depuis prism.
Support for Restoring Network Configuration during Host Break-fix : capacité de sauvegarde de la configuration réseau d’un noeud pour éventuellement la restaurer en cas de problème. Je ne sais pas concrètement comment utiliser cette option pour le moment.
PagerDuty Integration with Prism : Permet de créer des Playbook avec de nouvelle action pour envoyer des alertes à PagerDuty.
AOS Data-in-Transit Encryption : Permet le chiffrement des données échangés entre les nœuds ce qui n’était pas le cas auparavant et nécessitait l’isolation de ces flux.
En plus voici les améliorations associé côté hyperviseur AHV
Memory Overcommit : Vous allez enfin pouvoir allouer plus de RAM que ce dont vos serveurs disposent réellement, il y a pas mal de limitation, mais c’est une très bonne étape et cela fait un moment que l’on attendait cette fonctionnalité !
ADS Support for VMs with Virtual GPUs : Acropolis Dynamic Scheduling (ADS), l’équivalent DRS côté AHV prend en charge les vGPU donc si d’autres noeuds du cluster ont des ressources vGPU disponiblent et qu’il n’y a pas d’affinité VM-Hote, il pourra équilibrer la charge grâce à la fonction « Live Migration of vGPU-enabled VM » disponible depuis la 5.18.1.
Live Migration of vGPU-enabled VMs : ajout le support des migrations à chaud de VMs avec vGPU entre clusters, les GPU passtrought ne sont pas supportés, la VM nécessite d’être protégé par une réplication synchrone pour être déplacé entre cluster, la cible doit disposer des profils de ressources GPU adéquate et la VM ne peut pas être protégé en HA.
AHV VM templates : Nouvelle capacité disponible depuis Prism Central qui permet de gérer les templates, il faudra que j’approfondisse ce point par un petit article.
Category-based Host affinity policy : Permet de gérer les affinités entre VM et Hôte depuis Prism Central à l’aide des catégories.
Support for Separate Flow Networking based VPC Traffic : Permet de séparer le trafic des VMs à l’aide de Virtual Private CLoud (VPC) Flow plutot que les virtual switches.
Improved live migration of VMs : Je n’ai pas trouvé le détail des mécanismes utilisés, mais le live migration est facilité pour les machines très consommatrices de RAM.
Enhanced fault detection for High Availability : Ajout de deux vérifications supplémentaire pour déterminer la santé d’un hôte – Corruption du file system root et si le boot du system est en lecture seule. Déclenchement du HA si le système détecte un de ces deux états ou la perte du heartbeat avec le management de l’hôte, si le serveur reste dans cet état 40 secondes, les VMs qu’il héberge sont automatiquement redémarrées sur d’autres nœuds.
IGMP Snooping : Amélioration de la gestion du trafic multicast d’AHV, IGMP snooping permet à l’hôte de surveiller les VMs qui ont besoin du trafic multicast et de ne l’envoyer qu’à celle-ci.
Switch Port Analyzer on AHV Hosts : Permet la récupération de tout le trafic d’une interface d’un hôte AHV pour le rediriger vers une VM, ce serait un peu l’équivalent d’un promiscuous mode d’un virtual switch VMware.
J’espère que ce tour d’horizon vous aura plus, j’ai mis beaucoup plus de temps que prévu pour consolider toutes ces informations, mais je pense qu’il sera utile à beaucoup d’entre vous.